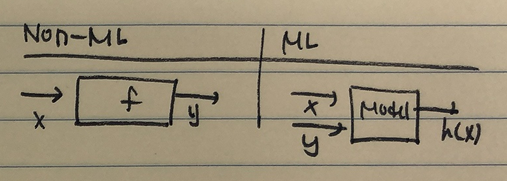전자공학/머신러닝개론
[머신러닝개론] 1.Introduction
문어인형
2023. 1. 9. 15:38
1. 머신러닝(ML)
- 기계에게 컴퓨터와 고양이를 어떻게 구분시킬까? Generalization
- ML approach? ① Data Collection ② Feature design ③ Model training ④ Model validation
|
Data Collection
|
Feature Design
|
Model training
|
Model Validation
|
|
여러 강아지, 고양이 사진을 모은다.
다양하고 많은 training set = 다양하고 많은 배움의 기회 |
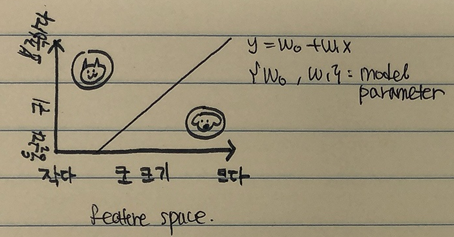
Feature: 각각을 구분지을 수 있는 특징
(ex) 개 vs. 고양이 : 귀의 크기, 코의 크기 Feature space y축: 귀의 뾰족함 정도 x축: 코의 크기 |
the training of model: ML problem이 기하학 적인 문제가 됨. parameter들을 mathematical optimization해야 한다.
model parameter: (ex) feature space가 2D라면, model) y=w0+w1x model parameter) w0, w1 |
validation set: previously unseen images
|
- Model 향상시키기 ① 더 많은 데이터 ② 더 많은 특징 ③ 비선형모델로 시도
- ML은 크게 두 카테고리로 나뉜다.
|
이름
|
역할
|
예시
|
|
지도학습
(Supervised learning) |
input&output 관계
|
Regression(prediction)
Classification(개vs고양이) |
|
비지도학습
(Unsupervised learning) |
input data only
입력 데이터의 특징 얻기 (데이터셋을 간단화하기 위해, 지도학습 전에 비지도학습을 시행할 때가 많다) |
Dimension reduction(model의 차원 줄이기, to squash or project)
Clustering(유사한 데이터 그룹화) |
2. Mathematical Optimization
- to minimize cost functions
- loss function (=cost function)
|
정답
|
yi
|
|
|
내 model
|
y = h(x;w) = w0+w1x
|
|
|
loss function
|
g(w) = Sum(h(xi;w) - yi)^2
|
|
- 즉, loss fucntion은 내가 만든 모델이 예측한 결과 y와 실제 정답 yi가 얼마나 차이가 나는지를 나타냄.
따라서 ML의 목표는 loss function을 최소화하는 것
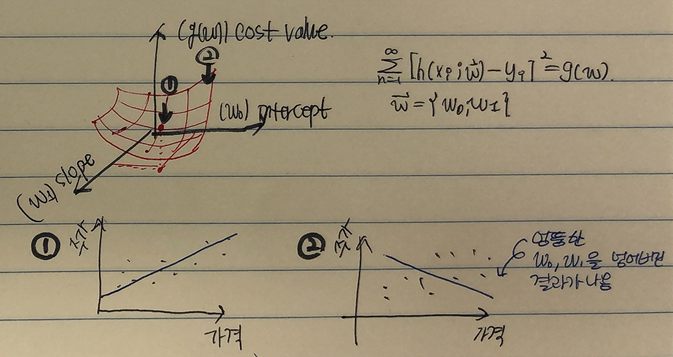

① w={w0, w1}를 갖는 model을 이용해 x0~x100의 input을 넣어 y0~y100의 output(예측 결과)를 얻는다
② 이 예측 결과 y0~y100을 실제 정답과 비교한다
③ 이 예측 결과 간의 차이가 가장 작은 걸 찾아내야 한다. 이는 즉, loss function을 최소화함을 의미한다.
+ Non-ML v.s. ML